Reseña — Designing Data-Intensive Applications — Capítulo 5
Reseña: Capítulo 5 — Consistencia y Replicación
Resumen
La replicación es el mecanismo fundamental para lograr que los datos estén disponibles en múltiples ubicaciones, permitiendo reducir la latencia, aumentar la disponibilidad y escalar las lecturas. Sin embargo, el verdadero desafío no está en copiar datos, sino en gestionar cómo se propagan los cambios, cómo se enfrentan los fallos y cómo se resuelven los conflictos cuando varias réplicas reciben escrituras simultáneas.
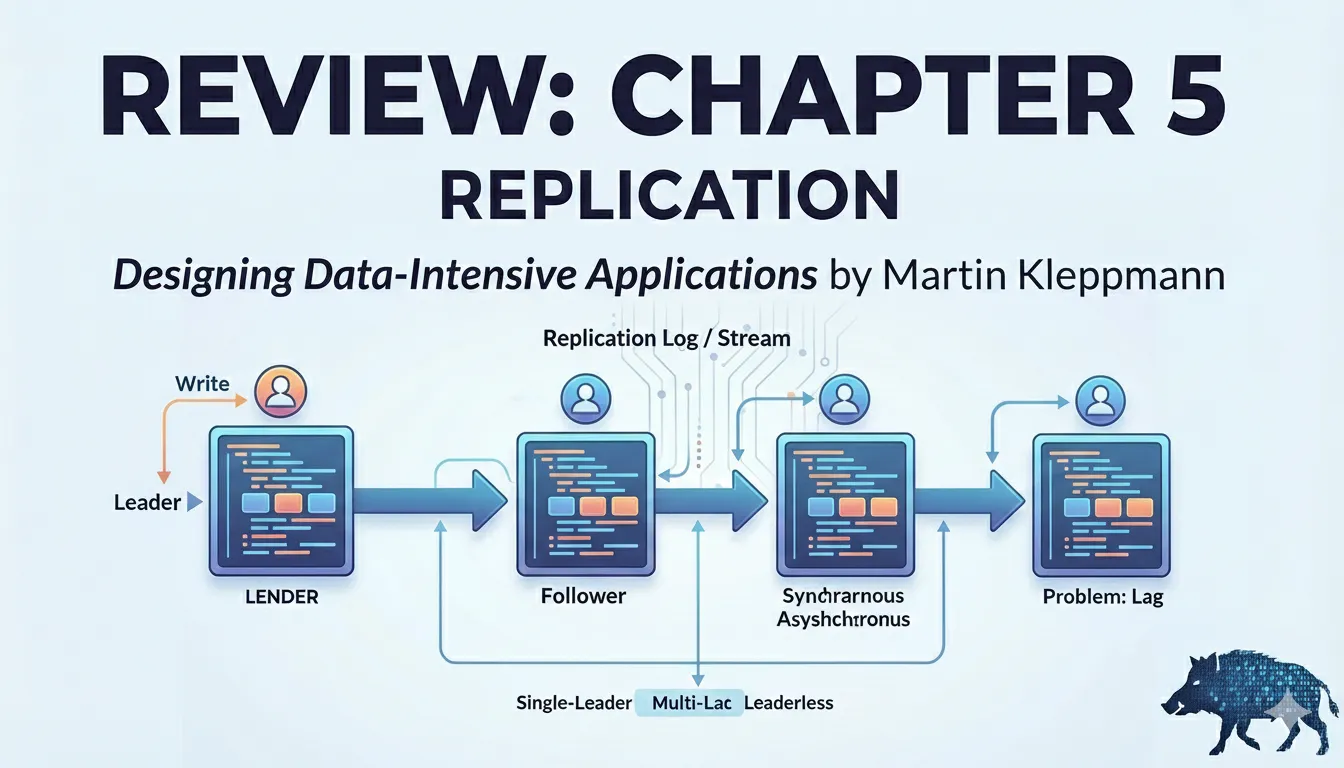
Kleppmann explica los tres modelos principales de replicación: un solo líder, múltiples líderes y sin líder (Dynamo-style), mostrando los compromisos entre consistencia, latencia y complejidad operativa. El capítulo destaca conceptos clave como quórums, vectores de versión y garantías de lectura/escritura, y los ilustra con ejemplos prácticos y lecciones del mundo real. El enfoque es ayudar a tomar decisiones informadas, entendiendo que cada modelo implica costos y beneficios distintos.
Modelos de replicación (breve)
-
Un solo líder: Todas las escrituras pasan por un líder que las ordena y las replica a los seguidores. Simplicidad operativa y lecturas coherentes desde el líder, pero el líder es un punto único de fallo y puede crear cuellos de botella en escrituras.
-
Múltiples líderes (multi-líder): Varios nodos aceptan escrituras en paralelo (por ejemplo, réplicas en distintos centros). Mejora disponibilidad y tolerancia a particiones, pero requiere estrategias de resolución de conflictos y puede introducir inconsistencias temporales.
-
Sin líder (leaderless / Dynamo-style): No hay un líder fijo; las escrituras se envían a un conjunto de réplicas y se usan quórums y metadatos (vectores de versión) para reconciliarlas. Alta tolerancia a fallos y baja latencia en algunos casos, a costa de mayor complejidad en la reconciliación de conflictos.
Tipos de conflictos
- Sobrescritura / pérdida de actualización: dos escrituras concurrentes sobre el mismo dato donde una sobrescribe a la otra y se pierde información.
- Conflictos semánticos: operaciones incompatibles (por ejemplo, una réplica realiza un
incrementomientras otra hace unaasignación) que no se resuelven correctamente sin lógica de la aplicación. - Divergencia de versiones: réplicas con estados diferentes que requieren fusión manual o resolución por el cliente.
- Duplicados o colisiones de IDs: inserciones concurrentes que generan entidades duplicadas o IDs en conflicto.
- Ordenación y causalidad: operaciones aplicadas en distinto orden en réplicas que provocan resultados distintos.
- Incompatibilidades de esquema/formatos: cambios en el esquema o en la representación de los datos que impiden una reconciliación automática.
Puntos clave
-
Sincronía vs asincronía: la replicación síncrona ofrece fuertes garantías pero penaliza latencia y disponibilidad si un réplica no responde; la replicación asíncrona es veloz, pero arriesga pérdida de datos si el líder falla antes de propagar la escritura.
-
Manejo de caídas y failover: promover un seguidor a líder debe evitar split-brain y duplicidad de escrituras; los protocolos de elección y reconciliación son críticos para preservar integridad (el incidente de GitHub es un ejemplo ilustrativo).
-
Costo del lag: el retraso entre escritura y réplica genera anomalías observables (lecturas antiguas, inconsistencias temporales) que hay que mitigar con políticas de lectura o diseño de UX.
-
Conflictos de escritura: en modelos multi-líder o sin líder pueden producirse escrituras concurrentes; las estrategias van desde resolución basada en versiones (vectores de versión) hasta delegar la fusión al nivel de la aplicación o usar estructuras convergentes (CRDTs).
Conceptos importantes
- Quórums (n, w, r): cuántos nodos deben participar para que una lectura o escritura sea considerada válida; la elección de w y r determina las garantías y la probabilidad de lectura after-write.
- Consistencia eventual: la promesa de convergencia si cesan las escrituras; útil en sistemas altamente disponibles pero insuficiente para muchas interacciones de usuario.
- Read-after-write: patrones para garantizar que un usuario vea su propia escritura (lecturas del líder, lecturas de quorum apropiadas, sticky sessions).
- Vectores de versión: técnica para rastrear causalidad y detectar concurrencia sin depender de relojes físicos.
Ejemplos y referencias
- Bases de datos tradicionales (MySQL, PostgreSQL, Oracle): replicación de un solo líder, relativamente simple y adecuada para muchas cargas.
- Sistemas Dynamo-style (Cassandra, Riak, Voldemort): replicación sin líder con quórums y resolución de conflictos en capas superiores.
- Protocolos de consenso (Paxos, Raft): ofrecen consistencia fuerte para metadatos o sistemas que requieren linearizability.
- Edición colaborativa (Google Docs, Etherpad): retos del multi-líder en tiempo real y soluciones basadas en OT/CRDT.
- Incidentes operativos (p. ej. GitHub): ejemplos reales de cómo un failover mal gestionado puede causar pérdida de datos o duplicados.
Conexiones con el Capítulo 1
Este capítulo aplica los pilares del Capítulo 1:
- Confiabilidad: replicación para tolerar fallos de hardware.
- Escalabilidad: añadir réplicas para escalar lecturas sin aumentar el almacenamiento primario.
- Mantenibilidad: réplicas permiten mantener nodos uno a uno sin downtime global.
Preguntas y temas para profundizar (Capítulo 6)
- ¿Qué pasa cuando los datos no caben en una sola máquina? El siguiente capítulo sobre particionado (sharding) aborda cómo dividir y distribuir datos en trozos manejables.
- ¿Cuándo conviene usar Raft/Paxos para metadatos y un sistema Dynamo-style para datos calientes?
- ¿Es mejor resolver conflictos en la aplicación o usar CRDTs para asegurar convergencia automática?
Notas y citas
- “Toda la dificultad de la replicación reside en manejar los cambios en los datos.”
- “La verdad en un sistema distribuido es definida por la mayoría.”
- “La replicación síncrona garantiza que el seguidor tiene una copia exacta, pero el líder debe bloquear todas las escrituras si el seguidor no responde.”
Checklist rápido (decisión de replicación)
-
¿Necesitas alta disponibilidad y simplicidad? Ve por un Solo Líder asíncrono.
-
¿Tienes múltiples centros de datos o necesitas trabajar offline? Considera Multi-líder.
-
¿Tienes una carga de escritura masiva y puedes resolver conflictos en la aplicación? Considera Sin Líder (Dynamo-style).
-
¿No puedes permitirte datos viejos bajo ninguna circunstancia? Necesitas replicación síncrona, pero prepárate para la latencia.
-
¿Es aceptable la latencia introducida por sincronización?
-
¿Cuántos nodos y cuál es el modelo de fallos esperado?
