Reseña — Designing Data-Intensive Applications — Capítulo 4
Reseña: Capítulo 4 — Evolucionabilidad (Data Evolvability)
Resumen
Este capítulo explora por qué la evolucionabilidad de los datos es una propiedad esencial —y muchas veces descuidada— en sistemas a largo plazo. Kleppmann plantea el problema desde la práctica: el código cambia con frecuencia (nuevas funcionalidades, correcciones, refactorizaciones) mientras que los datos suelen persistir durante años, por lo que diseñar formatos y procesos que permitan que distintas versiones de software coexistan sin romper el intercambio de información es crítico.
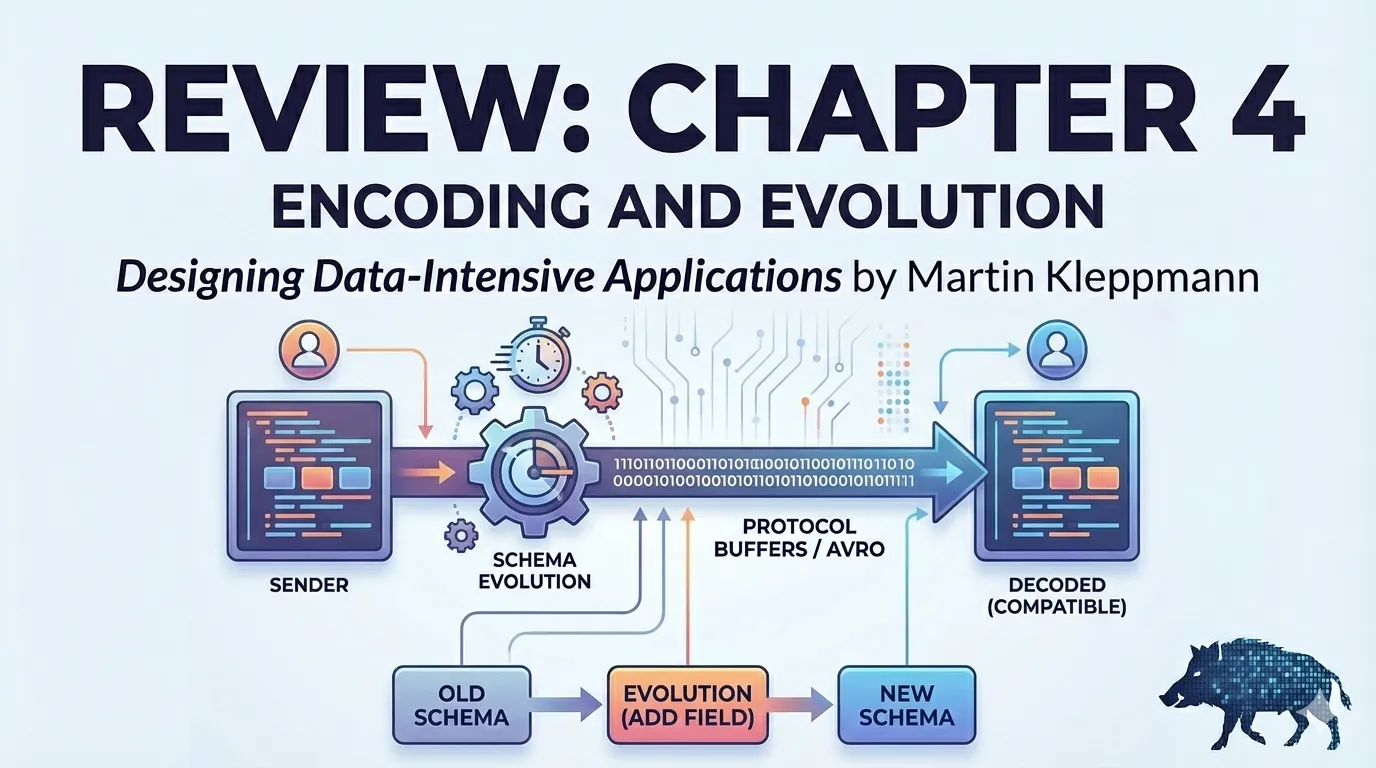
El autor analiza los mecanismos técnicos que habilitan esa coexistencia: esquemas que admiten campos opcionales, identificadores de campo (field tags) que permiten renombrar sin perder compatibilidad, y estrategias de serialización que separan el esquema de los bytes almacenados (p. ej. Avro). Kleppmann destaca la diferencia entre compatibilidad hacia atrás, hacia delante y la compatibilidad completa, explicando cuándo cada una es necesaria según el flujo de lecturas/escrituras y el patrón de despliegue (rolling upgrades, consumidores asíncronos, backfills).
Además, el capítulo compara el coste operativo de diferentes elecciones: los formatos textuales (JSON) facilitan debugging e inspección humana pero ofrecen poca disciplina de esquema; los formatos binarios con contrato (Protobuf, Thrift, Avro) añaden rigor y ahorro de espacio, pero exigen herramientas y procesos para evolucionar esquemas sin romper consumidores. Kleppmann también cubre patrones de despliegue y operación —migraciones en línea, transformaciones en lectura, y estrategias para eliminar campos obsoletos sin causar interrupciones— mostrando que la evolución de datos es tanto una preocupación de ingeniería como de organización.
Un insight práctico es que no existe una solución universal: elegir un enfoque depende del ritmo de cambio del esquema, la diversidad de clientes (multi-lenguaje), la visibilidad operativa y el coste del almacenamiento/transferencia. Para datos que deben permanecer legibles por humanos y donde la latencia operativa importa poco, JSON puede ser suficiente; para sistemas con alta ingestión, consumidores heterogéneos y requisitos de compatibilidad a largo plazo, un sistema basado en esquemas es más seguro.
Finalmente, Kleppmann recuerda que las decisiones de diseño deben instrumentarse: métricas de compatibilidad, pruebas de compatibilidad entre versiones y playbooks de rollback o migración reducen el riesgo de incidentes. La lección central es clara: pensar en evolucionabilidad desde el inicio (formatos, contratos, procesos) amortigua el coste político y técnico de cambios inevitables en sistemas de datos.
Puntos clave
-
La inevitabilidad del cambio
En sistemas grandes el despliegue no ocurre a la vez en todos los nodos; los upgrades se hacen de forma incremental (rolling upgrades). Por tanto, el código antiguo y el nuevo deben poder operar simultáneamente sobre los mismos datos sin romperse.
-
Compatibilidad bidireccional
No es suficiente garantizar solo compatibilidad hacia atrás (backward compatibility). La compatibilidad hacia delante (forward compatibility) también importa: el código antiguo debe ser capaz de manejar datos que potencialmente fueron escritos por versiones más nuevas.
-
El dilema del formato
Los formatos textuales (JSON, XML, CSV) son fáciles de inspeccionar y depurar, pero los formatos binarios (Thrift, Protocol Buffers, Avro) son más compactos y ofrecen mejores garantías para evolucionar esquemas sin romper consumidores.
-
Los datos sobreviven al código
Mientras que el código puede actualizarse en minutos, los datos pueden permanecer años en bases de datos con esquemas antiguos. Esto obliga a diseñar compatibilidad a largo plazo y procesos de migración cuidadosos.
Conceptos importantes
- Codificación (serialización): traducir estructuras en memoria a una secuencia de bytes para almacenamiento o transmisión.
- Esquema en lectura (schema-on-read): formatos como JSON donde la estructura se interpreta al leer.
- Esquema en escritura (schema-on-write): la base de datos/almacen exige una estructura definida al escribir.
- Etiquetas de campo (field tags): identificadores numéricos en Thrift/Protobuf que permiten renombrar campos sin romper compatibilidad.
- Esquema del lector y del escritor: en Avro, la biblioteca resuelve diferencias entre el esquema con el que se escribió y el que se está leyendo.
- Transparencia de ubicación: la ilusión (y fallo) de RPC de hacer que una llamada remota parezca local; Kleppmann recuerda que la red introduce fallos y latencias que no existen en llamadas locales.
Ejemplos y referencias
- Apache Thrift y Protocol Buffers: uso de identificadores numéricos para eficiencia y evolución de esquemas.
- Apache Avro: diseñado para flujos masivos (p. ej. Hadoop); guarda esquemas separados en lugar de etiquetas por campo, lo que reduce tamaño y facilita la resolución de esquemas.
- REST vs RPC: análisis de por qué REST se ha impuesto en APIs públicas por su bajo acoplamiento y facilidad para evolucionar sin romper consumidores.
- Actores y Message Brokers: referencia a arquitecturas (Akka, Orleans) y a brokers de mensajería que obligan a pensar en compatibilidad de mensajes asíncronos.
Crítica y comentarios
Kleppmann baja al nivel de los bits y los bytes con rigor: comparar el tamaño de un registro en JSON frente a Avro (p. ej. 81 bytes vs 32 bytes) es una llamada de atención para arquitectos preocupados por almacenamiento y ancho de banda.
Mi comentario: la sección sobre RPC es especialmente valiosa; el autor recuerda que la red es caprichosa —pérdida de paquetes, lentitud y variabilidad— y que ocultar esos hechos bajo una abstracción tipo llamada local ha causado problemas históricos en sistemas distribuidos.
Conexiones con el Capítulo 1
Este capítulo es la aplicación práctica del pilar de Mantenibilidad (y su subtipo, Evolucionabilidad) presentado en el Capítulo 1.
- Confiabilidad: la evolución de esquemas y los rolling upgrades están ligados a que el sistema siga operativo y no corrompa datos.
- Operabilidad: despliegues graduales y herramientas para gestionar versiones facilitan la operativa y reducen urgencias.
Preguntas y temas para profundizar
- Si los datos sobreviven al código, ¿estamos invirtiendo suficiente esfuerzo en diseñar procesos de migración y limpieza de datos antiguos?
- ¿Cuánto compensa usar formatos binarios respecto a perder la inspección humana que ofrece JSON durante debugging rápido?
Notas y citas
- “Los datos sobreviven al código” (Data outlives code).
- “La red es fundamentalmente diferente de una llamada a una función local”.
- “La evolucionabilidad es la facilidad con la que puedes hacer cambios a un sistema de datos.”
Checklist rápido para elegir formato de codificación
- ¿Necesitas que los humanos lean los datos fácilmente? Elige JSON/XML.
- ¿El ancho de banda o el almacenamiento es extremadamente caro? Elige Avro o Thrift/Protobuf.
- ¿Tu esquema cambia con mucha frecuencia? Avro es ideal porque permite esquemas dinámicos sin etiquetas manuales en los datos.
- ¿Trabajas en un entorno multi-lenguaje (Java, Python, C++)? Evita serializaciones nativas y usa estándares (Protobuf/Thrift).
- ¿Quieres documentación que actúe como contrato vivo? Los formatos basados en esquemas binarios sirven como contrato y documentación que no se desactualiza fácilmente.
